UNDER THE HOOD
Currently, CraveIT is a proof-of-concept: it focuses on the city of Rome, and features a selection of 15 traditional dishes. However, it has the potential -and we hope soon the opportunity- to expand to any town and to include any dish.
DATA GATHERING & CLEANING
CraveIT’s PoC is built on the analysis of over 1.000.000 reviews, gathered from the most influential information hubs of the food industry. This pool of reviews covers approximately 2.500 of the best (top 20%) and more visited (top 10%) restaurants in Rome. For each of these restaurants, we collected all the reviews written in the past 5 years, along with a rich set of contextual information about both the reviews (title, score, date, etc.) and the restaurants (price range, location, contact info, opening hours, features, etc.).
The pool of raw data then underwent a fine-grained pre-processing pipeline. Each review and its contextual attributes has been checked for formal and semantic consistency. Furthermore, duplicates, missing and null values have been handled through solutions tailored to the importance of each variable. Data from different sources have then been merged: each review, regardless of its origin, has been augmented with aggregated information from all the other sources as well, resulting in a rich, and so far unavailable, dataset. Finally, the results have been filtered to include only reviews of Italian restaurants, and written in Italian.
INDEXING & RETRIEVAL
To identify pieces of text mentioning at least one of our 15 target dishes efficiently and in a scalable manner, we indexed the bodies and titles of the reviews in batches using a search engine. We then built queries to capture not only matches, but also misspellings and morphological variants of the target terms. For multi-word dishes (e.g. “cacio e pepe”), we devised custom solutions to ensure accurate retrieval.
SENTIMENT ANALYSIS
After identifying the specific set of reviews mentioning each of our target dishes, we proceeded to the phase of sentiment analysis, which presented a significant challenge. The uniqueness of CraveIT lies in its ability to provide dish-specific recommendations. However, we had to address the fact that users often discuss multiple dishes within the same review, along with general feedback on the restaurant’s overall features. For our sentiment analysis we thus employed different state-of-the-art pre-trained transformer models, tailoring the input data format. Depending on the context, the models were fed either the entire review or relevant portions of it, focusing on the chunks most likely to reflect opinions about each specific dish. The models then produced sentiment scores ranging from 1 (very negative) to 5 (very positive) for each dish mentioned in the review.
The results were outstanding and far exceeded expectations. Remarkably, the models demonstrated the ability to automatically recognize when a review did not express a specific sentiment about a dish, even without explicit prompting. For example, the models could recognize instances where users mentioned a dish was on the menu but did not actually try it. More importantly, the models captured subtle nuances of meaning and distant dependencies within the text. This becomes particularly clear if we merge together the results that the models got, in different iterations, on reviews that were mentioning multiple dishes:
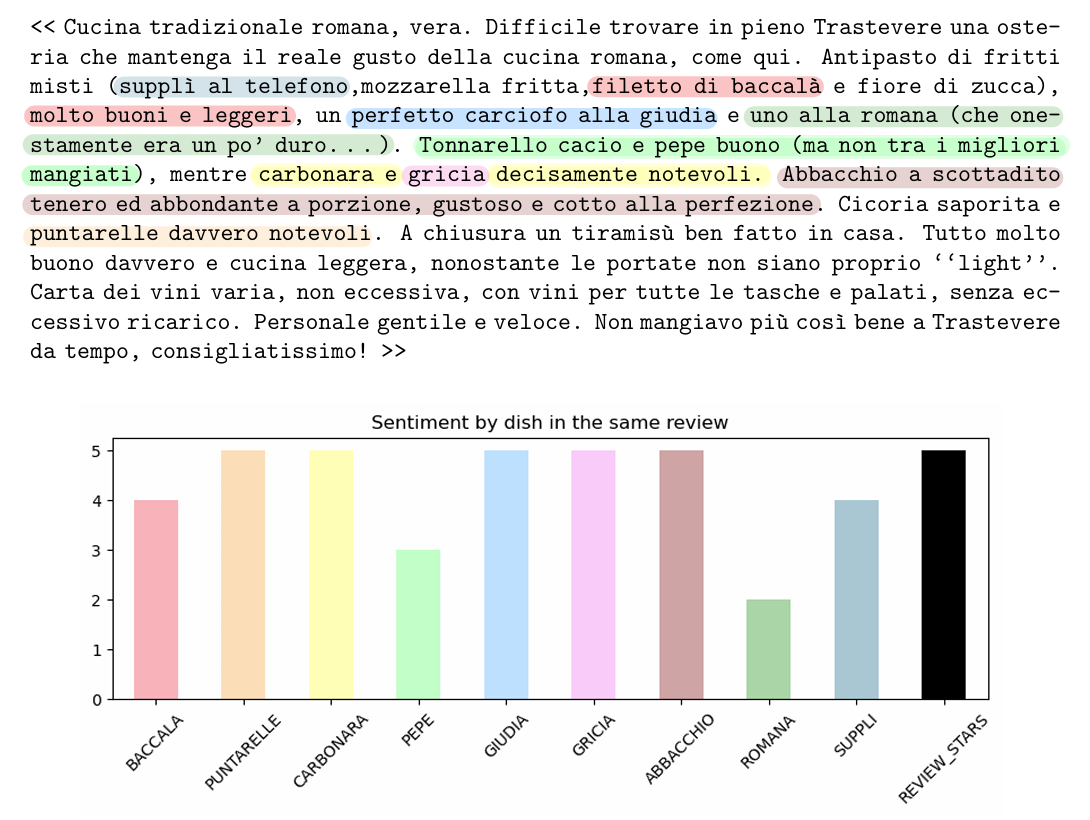
The models successfully pinpointed the sentiment associated with the target dish, effectively filtering out irrelevant comments about other dishes, service, or the restaurant in general. This capability is particularly crucial since the overall stars assigned by the users, on which traditional apps rely for their rankings, lack the necessary granularity to pick up on the full range of the opinions expressed in the text. We argue that this limitation causes current platforms to overlook and lose a lot of prime information along the way. In contrast, the dish-specific sentiment analysis will give CraveIT a much more precise and detailed base for its ranking algorithm.
RANKING
CraveIT’s ranking algorithm uses 3 main parameters, all of which are dish-specific:
- mean sentiment: for each restaurant and each dish, this parameter is calculated as the average sentiment score derived from all relevant reviews, as determined by the models. The results from different models are weighted according to their accuracy and the extent of the context they analyzed.
- popularity: this parameter is defined as the ratio of reviews mentioning a specific dish at a particular restaurant to the total number of reviews referring to that dish across all restaurants.
- freshness: the ratio of the reviews mentioning a dish in that restaurant that were written in the past two years to the total of reviews mentioning that dish in that restaurant.
The combination of popularity and freshness ensures that CraveIT’s ranking is highly reliable. The sentiment score associated with a dish at a particular restaurant is weighted by the number of reviews it is based on, as well as how recent those reviews are. This approach prevents us from recommending a restaurant based on just a few reviews or outdated feedback that may no longer reflect the current quality of the food. Finally, we incorporated experts’ opinions by adding a flat score for every guide (Michelin, Gambero Rosso, Identià Golose) in which the restaurant is featured.
We aggregated all of these parameters with a normalized weighted sum that returned, for each restaurant-dish pair, a number between 0 and 10: our CraveIT score.